Transform your Raw, Scattered data into Perfect And Trusted Process Intelligence
Data.
Evidant’s >Data Transformation Refinery (DTR) takes messy enterprise data and transforms it into analytics-ready, high-quality process data — enabling faster projects, stronger insights, and safer AI.
Why DTR
Generic pipelines move data. Only DTR makes process data trustworthy, reusable, and business-ready.

Process-aware by design
Builds event logs, cases, timestamps, and activities automatically — the foundation for process mining and analytics

Data quality built in
Ensures accuracy, completeness, consistency, timeliness, and traceability at every step
Reusable and industrialized
Stop reinventing brittle ETL for every project. Use proven templates and governed pipelines
Works with your stack
Complements you current data preprocessing: SQL, ETL, Databricks,Teradata, Snowflake, and other pipeline tools
From ingestion to delivery — a transparent, auditable process data refinery.
Ingest, Refine, Deliver
Unlike data processing methods such as ETL, designed for IT professionals, our DTR is designed for business people so they can effectively refine data, resulting in better analytics and fast, confident decision making.

Ingest
Collect raw data from ERP, CRM, Workflows and lagecy appsRefine
Cleanse & Harmonize
Fizes daps, dligns IDs antiestanos. Standardizes across silos
Case & Event Builder
Fizes daps, dligns IDs antiestanos. Standardizes across silos
Validate & Govern
Quality dates, lineage and audit packs ensure trust
Deliver
Feeds refined logs back into analytics, BI and AI platforms.

Executives
Faster time-to-value on transformation projects. Lower cost, fewer overruns.
Reliable KPIs, audit-ready insights.

Consultancies
- Deliver projects faster with reusable pipelines.
- End “bad log” debates and client disputes.
- Build recurring services with continuous data feeds.

Data Engineers
- Works with existing platforms — no rip-and-replace.
- Automates event log creation & harmonization.
- Includes data contracts, versioning, and lineage.

AI & ML teams
- Reliable training and inference data reduces LLM hallucinations.
- Supports retrieval-augmented generation (RAG) with clean, enriched context.
- Continuous refreshes keep models grounded and accurate.
How the DTR Works
Generic pipelines move data. Only DTR makes process data trustworthy, reusable, and business-ready.
Rule Driven Data Pipeline
Unlike task graphs or generic workflows, DTR is rules-driven. Pipelines are structured as:
Refinery
→ Nodes
→ Transformers
→ Rules (+ Sub-rules).
This hierarchy makes transformations transparent, auditable, and easy to extend with reusable sub-rules.


Built-in Ingestion
DTR comes with ingestion nodes for common enterprise sources:
- Excel,
- Text,
- Feather,
- Databases,
- REST APIs.
Streaming support
Designed for high-performance streaming services for row and column transformations on operational and timestamped data.
Where transforms Run
All transformations execute inside the DTR engine via Processor Nodes with configurable Transformers.
Orchestration& Scheduling
Pipelines in DTR run in a sequenced manner: Refinery → Node → Transformer → Rule execution.
Each transformer checks its own processing completeness and is dependent on the processing completeness of connected ingests and transformers earlier in the pipeline
Use Cases
Use Cases by industry

Unify Patient Journey
- EHR
- Lab
- Billing systems
- Etc

Outage-to-resolution
- SCADA
- CRM,
- Field apps
- Etc

Citizen journeys
- Case management
- Portals
- Etc

Omnichannel insight
- POS
- E-commerce
- CRM
- Support
- Etc
Why DTR vs Generic Pipelines
Snowflake, Databricks, Teradata, and KNIME excel at moving or analyzing data — but none are process-aware by design. Only DTR:
– Structures pipelines with Rules and Sub-rules for clarity and governance.
– Provides built-in connectors for Excel, Databases, and REST without coding.
– Delivers event- and activity-based data streams joins out of the box.
– Runs transformations in its own engine with full lineage.
– Ensures sequencing and auditability tailored for process data.
Visual: a competitive grid showing checks for DTR against the others, reinforcing its unique position as a ‘Process Data Refinery.’
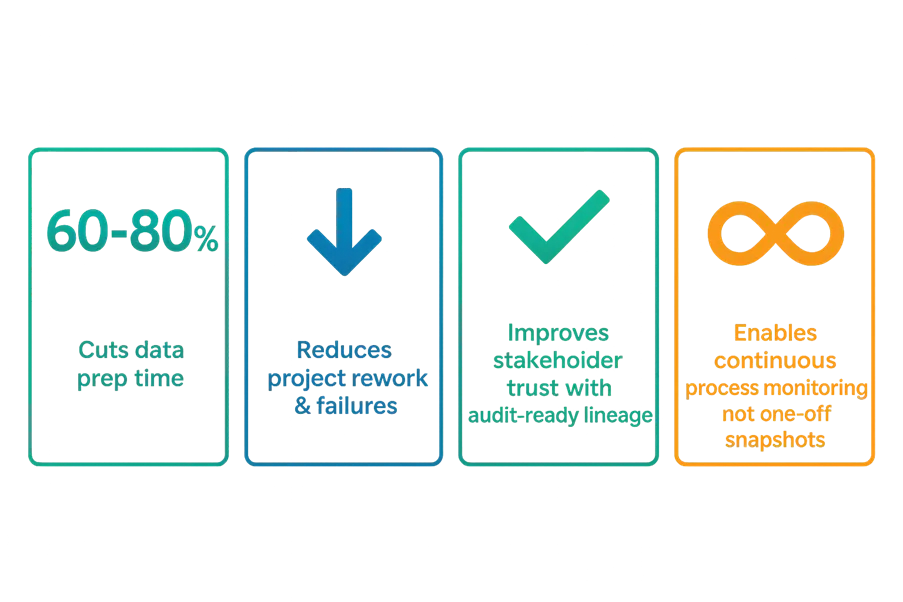
Proof & Outcomes
Real, measurable impact from day one.
Ready to stop fixing data and start delivering insights?
Join the consultancies, enterprises, and AI teams already using Evidant’s DTR to industrialize process data preparation.
Become a service provider
Interested in becoming part of the Evidant partner ecosystem?
We’re working with consultancies, system integrators and process intelligence vendors across Europe to make process data transformation faster, more reliable, and more profitable.
Togheter with our partners, we make process data a foundation for continuous transformation
Generic pipelines move data.
Evidant’s DTR turns data into trustworthy process intelligence — the foundation for faster analytics and safer AI.
Our Service Providers and Partners
Based in the Netherlands, Data Service Provider Conify provides data transformation and datapreprocessing services for process intelligence and –analytics

Based in the Netherlands and Portugal, Wassching combines cutting-edge process intelligence with experience engineering to create operational breakthroughs that truly matter.
Based in the Netherlands, the Agilos business consultants focus on process mining, risk management and IT security.